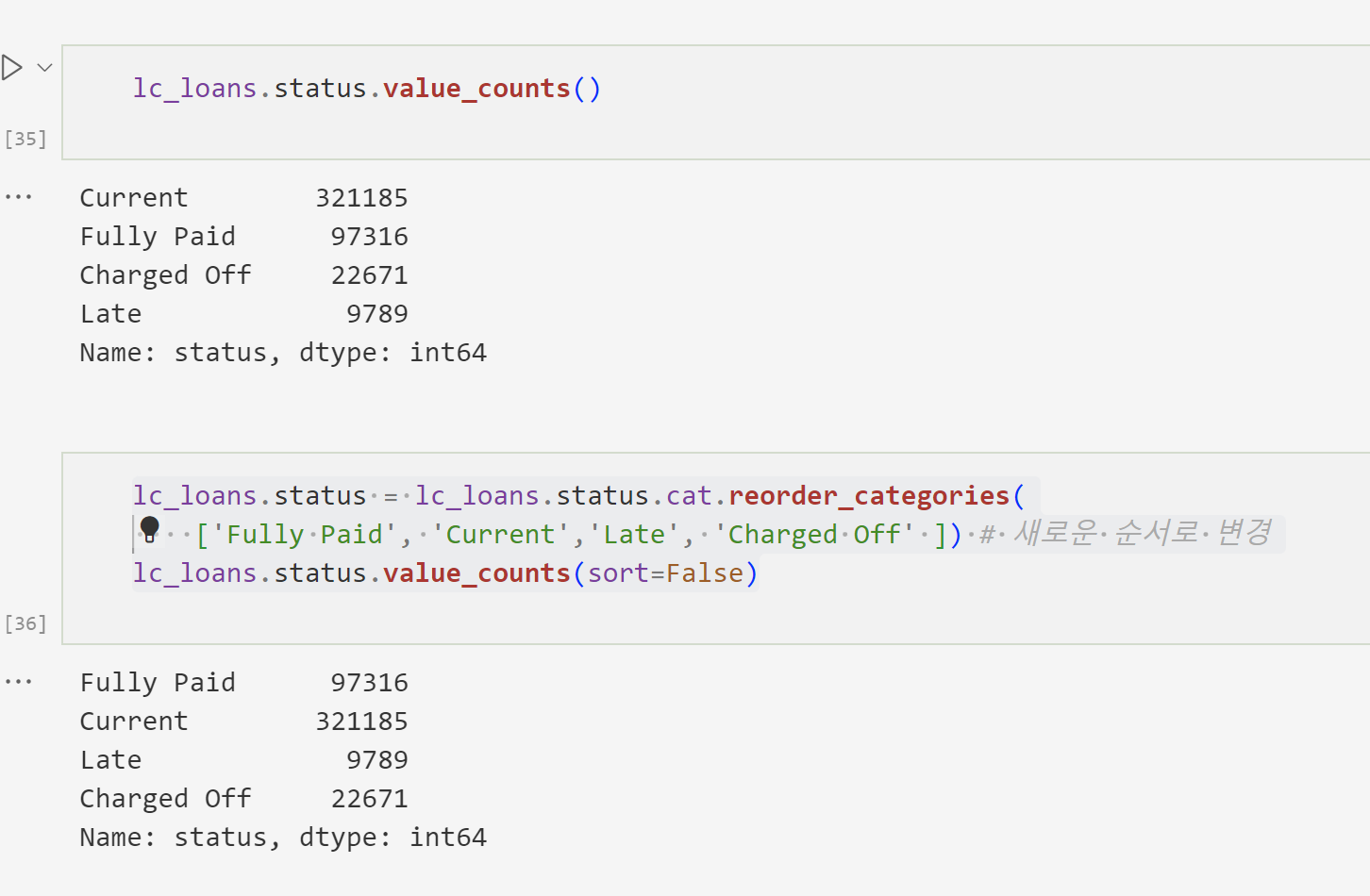
명목형 자료를 순서형으로 바꾸기위한 단계
1. 타입을 카테고리로 변경 astype('category')
>> 원래의 순서를 확인하고 싶다면 df['feature'].cat.categories
아마도 cat은 category의 약자인듯
2. 타입이 바뀌었는지 확인 후 cat.reorder_categories(['순서재정렬'])
후 vlaue_counts(sort=False) 하면 확인됨
카테고리 정렬 전 순서를 알고 싶다면 cat.categories 사용하면 된다.

df.value_counts(normalize=True) 비율로 바꾸는 방법 normalize
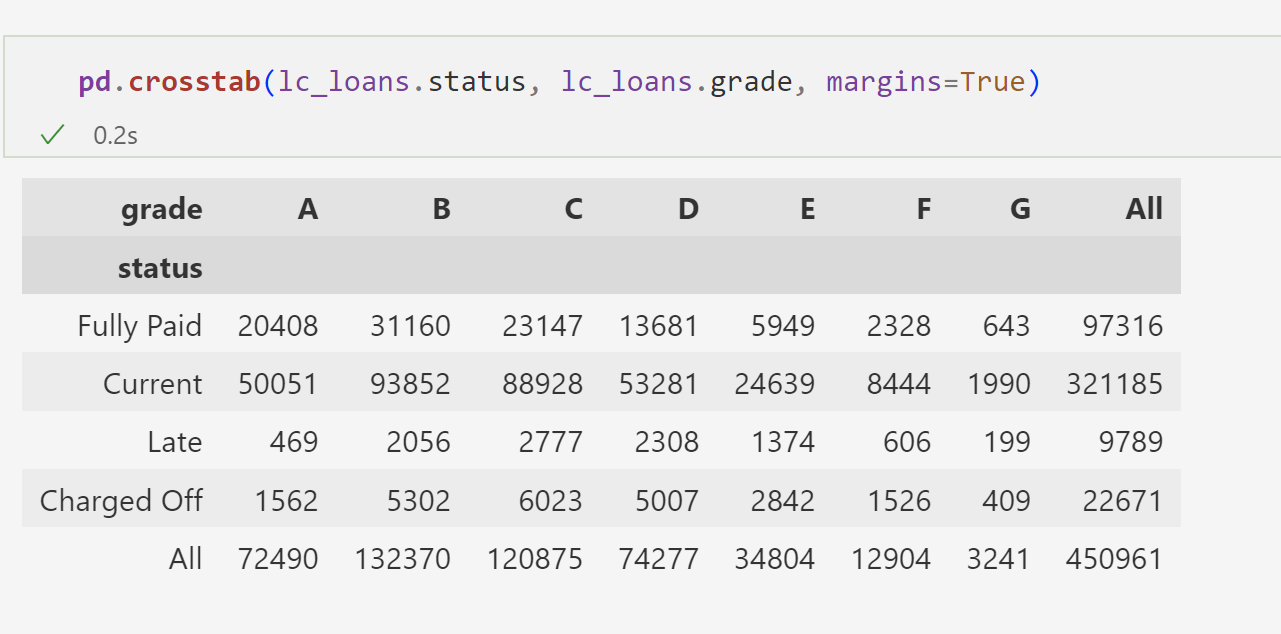
여기서 얻을 수 있는 인사이트는?
fully paid의 그레드의 비율을 알고 싶은것
퍼센트를 알고 싶다면 normalize= index 혹은 normalize=column 을 넣는다.
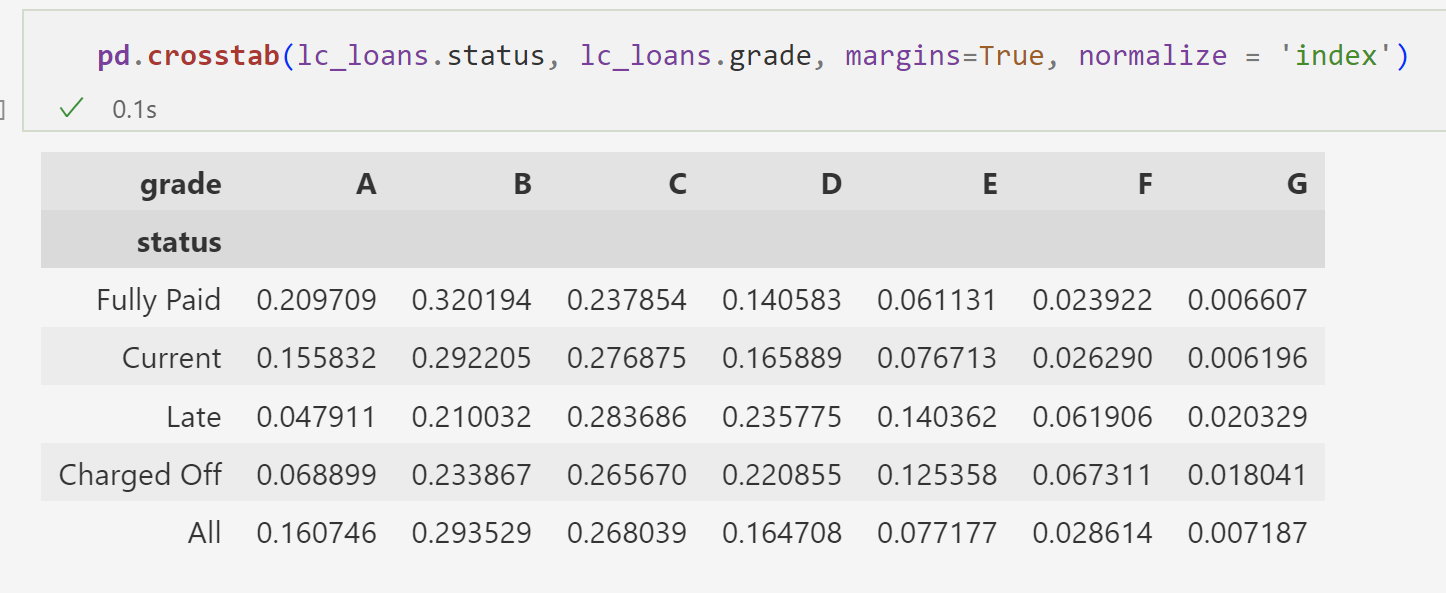
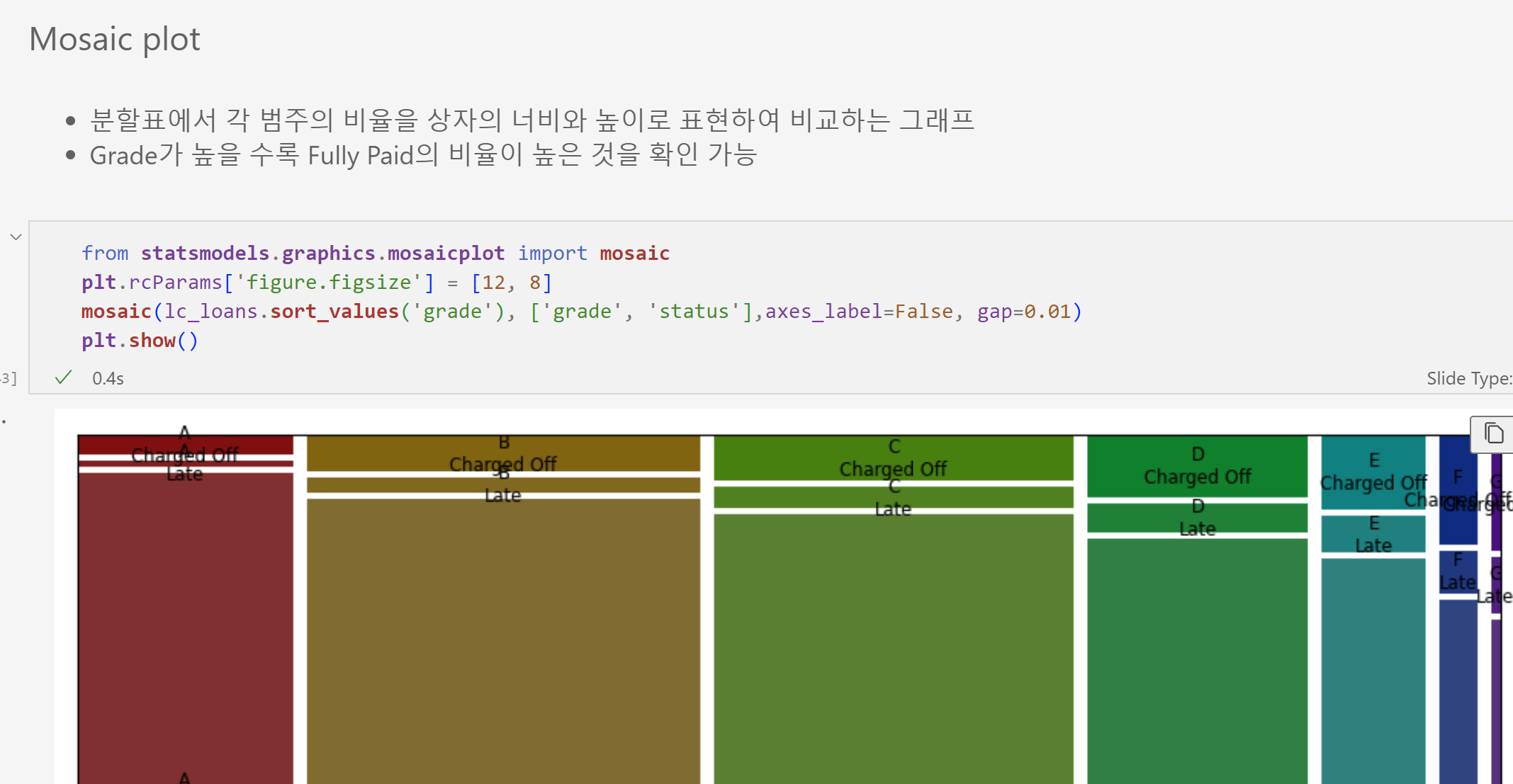
가로 너비로 전체의 너비를 예측할 수 있다.
세로는 상환 상태를 알 수 있다.
fully paid를 보면 a 비율이 가장 높음을 알 수 있다.
위 의 mosaic plot의 기준은 컬럼 기준임을 알 수 있다. 기준이 grade
아래는 status 기준의 비율이다.
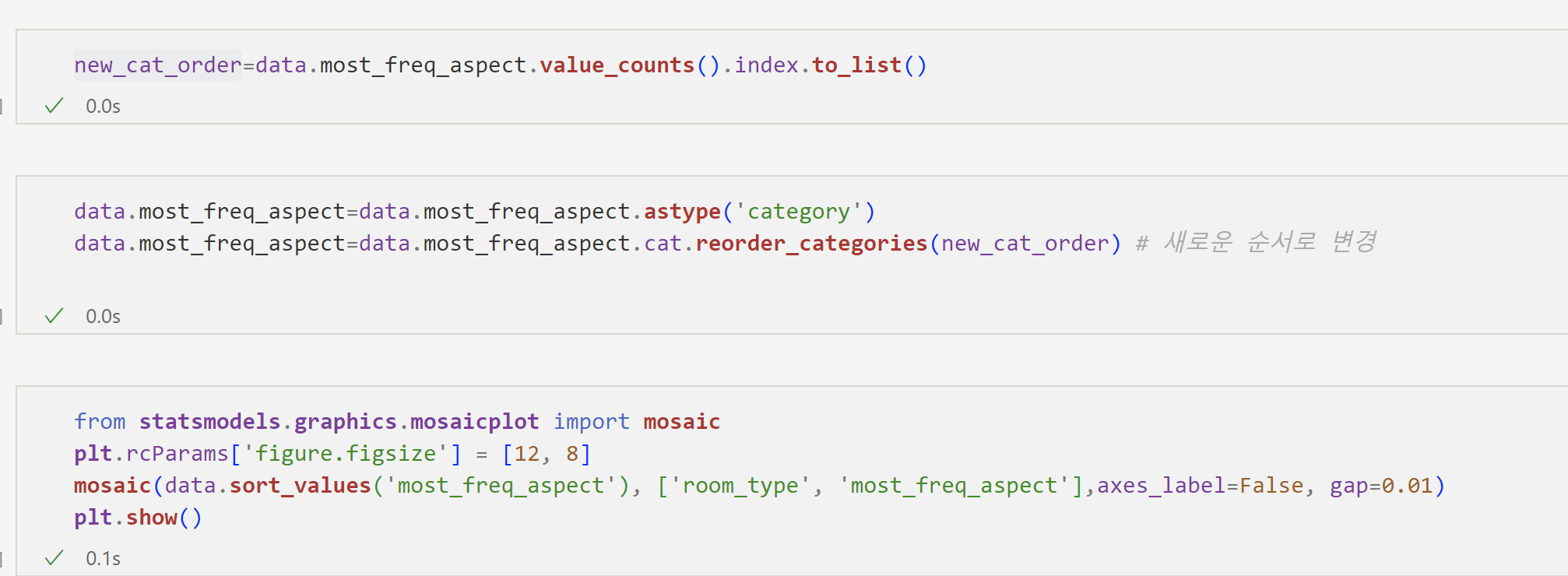
1. `data.sort_values('most_freq_aspect')`: 데이터프레임 `data`를 'most_freq_aspect' 열을 기준으로 정렬합니다. 이는 데이터를 'most_freq_aspect' 열의 값을 기준으로 오름차순으로 정렬하게 됩니다.
3. `['room_type', 'most_freq_aspect']`: 모자이크 그래프에서 x 축과 y 축에 표시될 열을 지정합니다. 'room_type'이 x 축에, 'most_freq_aspect'가 y 축에 표시될 것입니다.
4. `axes_label=False`: 이 부분은 x 축과 y 축의 레이블을 표시하지 않도록 설정하는 것으로 보입니다. 따라서 그래프에 축의 레이블이 표시되지 않을 것입니다.
5. `gap=0.01`: 모자이크 그래프의 각 범주 사이의 간격을 설정합니다. 간격은 0.01로 설정되어 있으므로, 각 범주 사이에 매우 작은 간격이 있을 것입니다.
따라서 이 코드는 'most_freq_aspect' 열을 기준으로 정렬된 데이터프레임을 사용하여 'room_type'과 'most_freq_aspect' 열을 가진 모자이크 그래프를 생성하며, x 축과 y 축의 레이블을 표시하지 않고, 각 범주 사이에 작은 간격을 두는 것으로 보입니다. 코드의 나머지 부분이 어떻게 동작하는지에 대한 자세한 내용은 더 많은 컨텍스트가 필요할 것입니다.
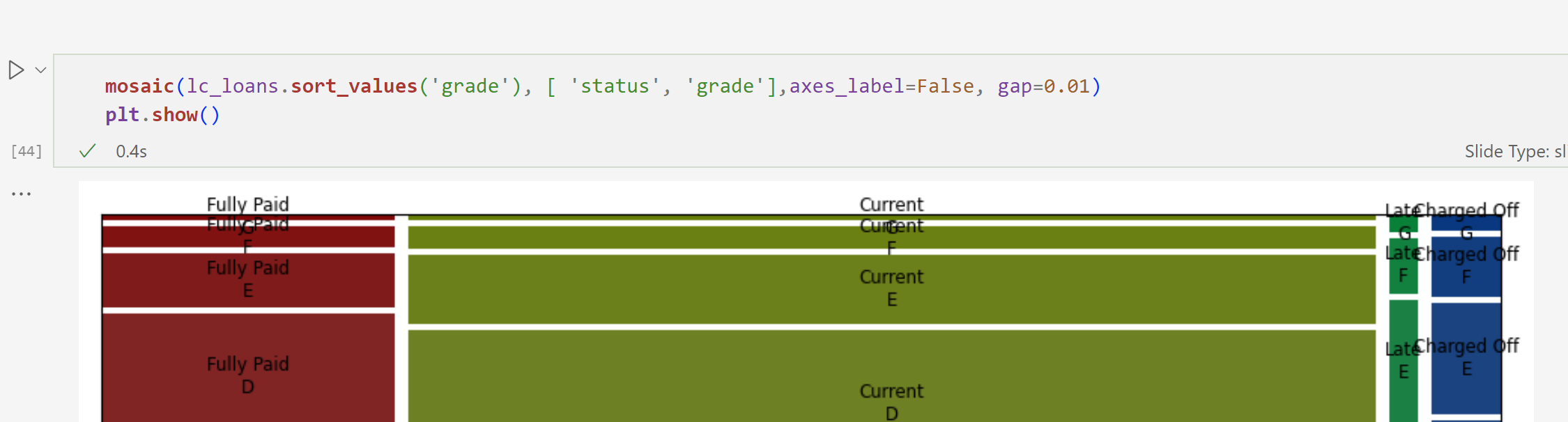
숙제 moasic plot 보기 너무 힘들다
범주형을 카테고리를 타입 변경을 한 후 순서형으로 바꾼 후 적용
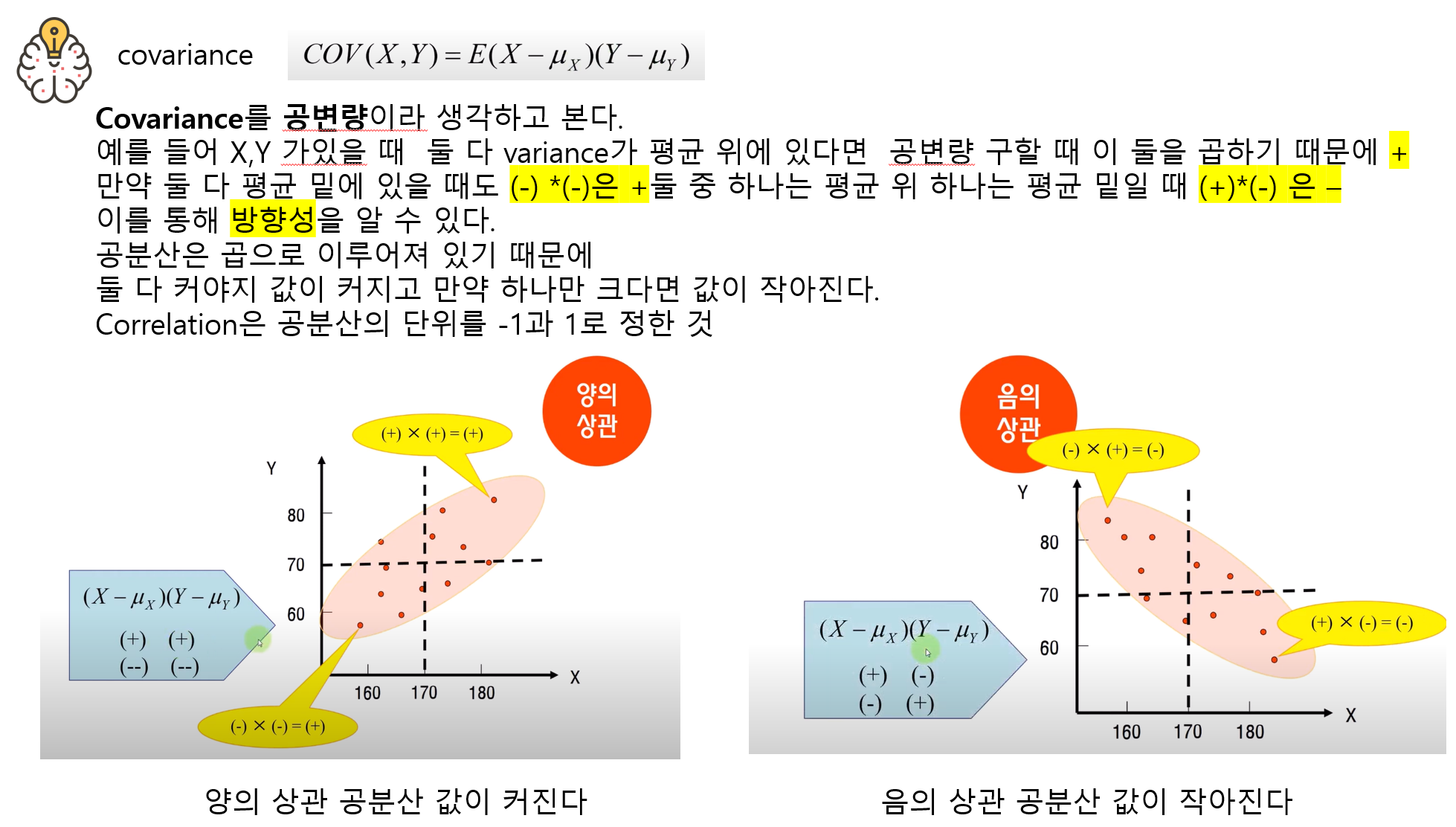
상관계수의 절대값이 클수록 큰 상관관계를 가진다.
절대값!
pearson 상관계수는 직선관계의 정도를 나타낸다. !
분석하기 전에 scatter랑 상관정도를 확인해야한다.
피어슨 상관계수는 직선에서만 적용되기에 직선이 아닌 관계에서 상관계수가 매우 낮게 나온다.
선형관계만 나타내는 함수
따라서 피어슨 상관계수와 scatter plot을 봐서 선형인지 비선형인지 파악
즉 비선형일때 피어슨 상관계수는 맞지 않다.
선형적일때만 의미가 있다.
피어슨과 scatter 같이 보기 !


베이즈 정리 첵/ 확률변수 개념 첵 / 확률분포 첵
유툽 영상확인하기
무작위 하나를 추출했을 때 그것이 불량품이고 그것이 a에서 생산될 확률
p(a|x)
탐과 마담의 예시 베이즈 정리 예시 자료 확인 (꼭)


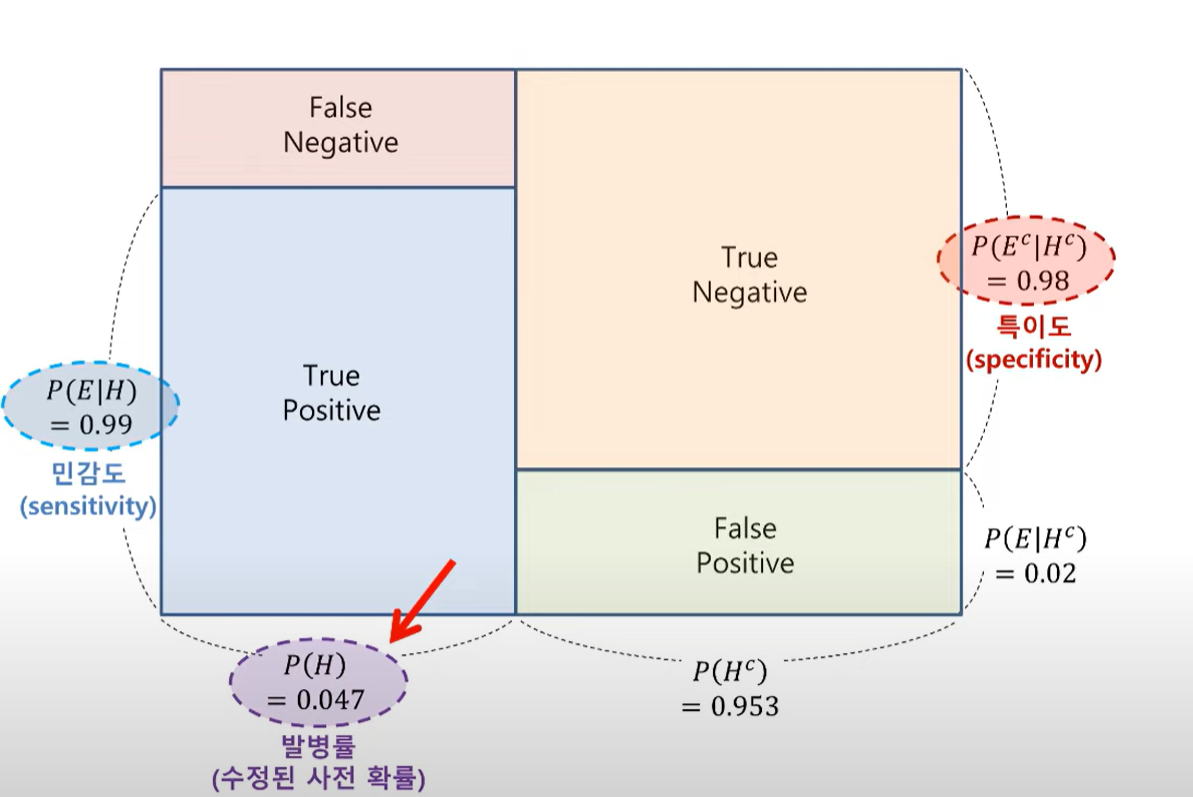
p(h) 사전확률 이는 가설 즉 병일 걸렸다 합격을 했다 등으로 표현할 수 있다.
p(e)는 증거
p(h/e) 사후확률로 e라는 증거를 통해 사전확률이 업데이트 되었다고 볼 수 있다.
귀납적 추론으로 볼 수 있다.
보통 확률은 연역적 기반으로 되어있다. '즉 베이즈정리는 신뢰도의 갱

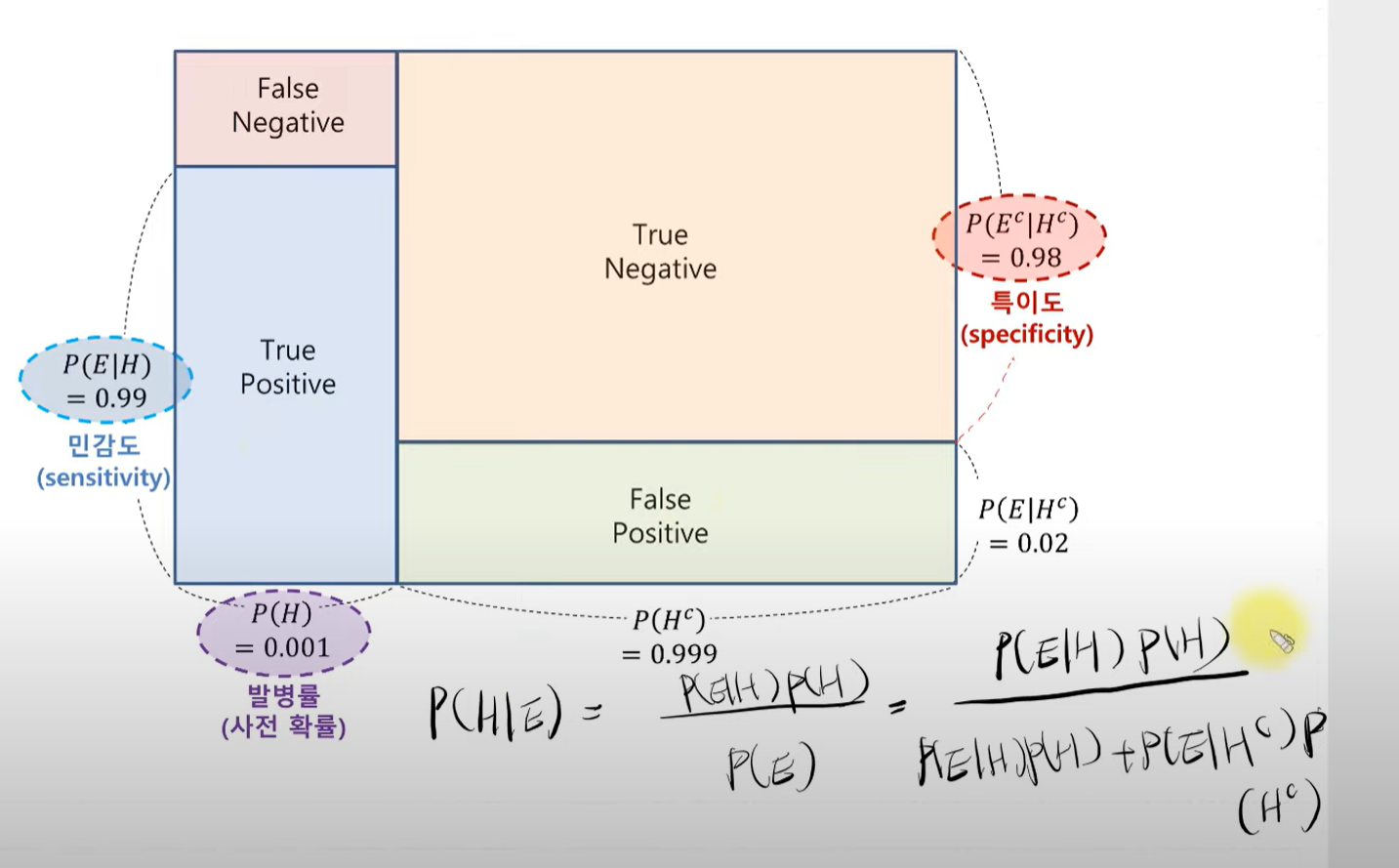
위 그림으로 이해를 한다면 결국 사후확률 계산은 초록색 파란색 더한것 분에 파란색 면적임을 알 수 있다.

예제 1을 통해 사전확률이 업데이트 됨을 알 수 있다.
즉 신뢰도가 갱신되었다. 그림 역시 수정되었다.


독립사건의 예는 내가 라면을 먹었을 때 별똥별이 떨어질 확률 같은거
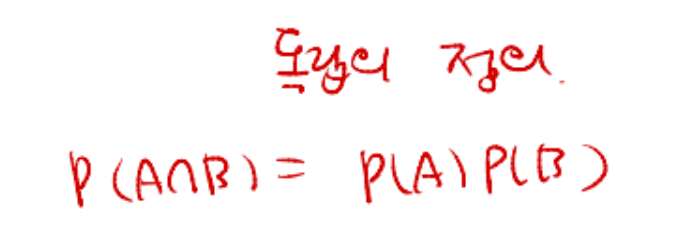
example 엔진 불량 리스크
엔진 두개가 독립적이라고 가정하는것
그렇다면 어떨때 독립이 아닐까?
버드 스트라이크 생각하면 한쪽만 들어가지 않을꺼야
example 유아돌연사 증후군
주가 나 시계열 데이타의 경우 독립일 수 없다.
그런것들은 독립으로 가정을 하고 모형을 돌리면 잘못될 수 있다는 것 명심
확률변수라는것은

어떤 사건을 실수로 만들어주는 변수

확률질량함수 pmf
확률밀도함수 pdf
이항분포 다음시간에 예습
숙제 리뷰



'2023_2 통계' 카테고리의 다른 글
| 검정통계량 tvalue (1) | 2023.10.12 |
|---|---|
| 정규화 하는 과정에서 어떨때는 표준오차로 나누고 어떨때는 표준편차로 나누는가? (0) | 2023.09.28 |
| 4_표준편차 표준오차 ^p (0) | 2023.09.24 |
| 분산을 구할 때 n으로 나눈는 문제 (0) | 2023.09.21 |
| 3_ (0) | 2023.09.17 |

